What is a duplicate case?
A duplicate case is an entry that has occurred more than once in the data-set. For example, a patient's record might have been entered more than once accidentally in the data-set and we would want to identify them.
How to identify the duplicates?
When we are entering big data, some cases might be entered more than once (e.g. by mistake). In that case, we can identify duplicate entries using SPSS. The following steps tell us how to identify the duplicates:
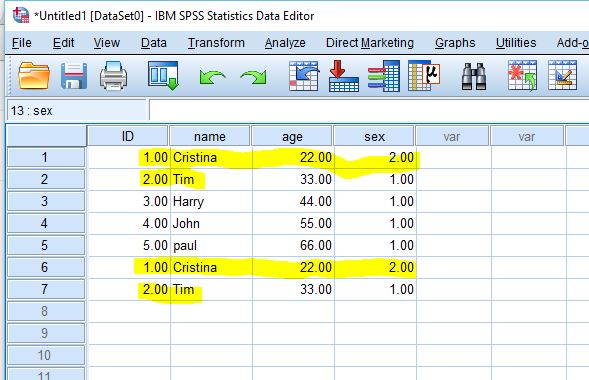
Step 1: Open the dataset in SPSS.
Step 2: Choose a variable that is unique identifier for each person or case in the data. For example, ID could be a unique identifier. If the ID is repeated more than once, we can assume that the case has a duplicate entry.
Step 3: Go to data, and click on identify duplicate cases.


Step 6: Set the variable that defines the duplicate cases. By default, the variable name "PrimaryLast" is created. You can rename the variable to put any desired name.
Step 7: Click ok and the following output is displayed which shows the number of duplicate cases in the dataset.

Step 8: The following change occurs in the dataset as well.

Step 9: Now, you can do anything with the duplicates (delete them; deselect them using select case feature etc.)
Hope you enjoyed the tutorial! Share it if you liked. See you in the next tutorial!
how can i mark the cases that has duplicates (both primary and duplicate) as opposed to cases that dont have duplicates?
ReplyDeleteThis is very educational content and written well for a change. It's nice to see that some people still understand how to write a quality post.! 警察 不祥事
ReplyDelete